Hydro:把超参数搜索放进流水线空泡
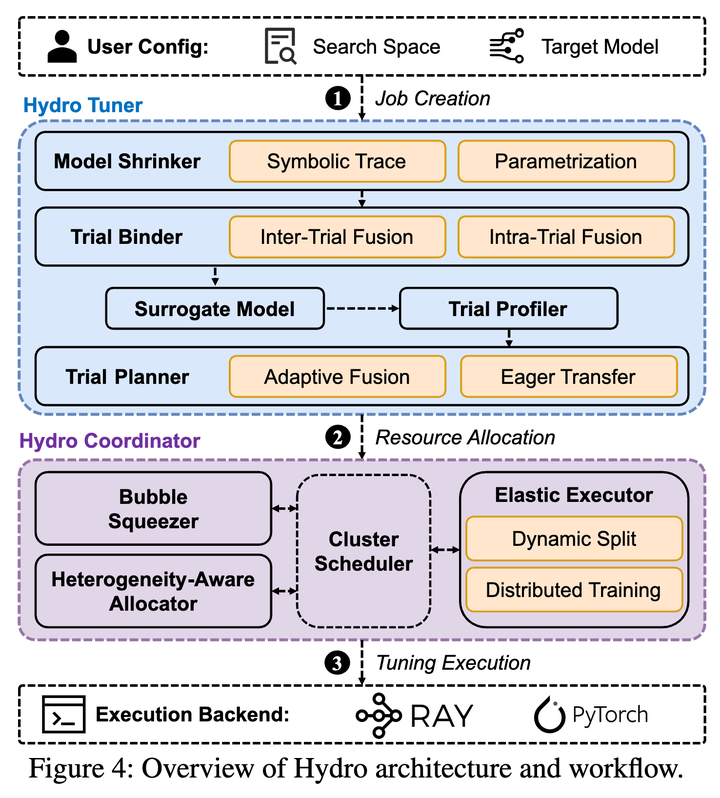 Hydro system design
Hydro system design
超参数搜索曾经像是一种可以接受的成本。训练很多个模型,扫几组 learning rate 和 batch size,然后留下最好的那个。它很贵,但仍然属于正常工程节奏的一部分。
后来模型大到一定程度,这个心智模型悄悄失效了。
如果训练一个模型本身就已经占用 GPU 集群的大块资源,那么传统 hyperparameter sweep 几乎显得荒唐:系统要求我们训练很多个高度相似的模型,而其中大多数只是为了被丢弃。更糟的是,已有 tuning framework 通常只看自己被分配到的资源。它们并不知道周围的集群里可能存在空闲 GPU 碎片、异构加速器,或者带有周期性空泡的长时间 pipeline-parallel 训练任务。
Hydro 从一个简单问题出发:能不能让 hyperparameter tuning 少一点 brute force,多一点 systems thinking?
Hydro 有两面。在任务层面,它通过调优更小的 surrogate model 让每个 trial 变便宜。在集群层面,它问了一个更有意思的问题:数据中心能不能用当前被浪费的 GPU 时间来运行这些便宜 trial?
先让 Trial 变小
Hydro 的第一步,是尽可能避免直接调优 target model。它缩小模型,调优小模型,再把找到的 hyperparameter 转移回原模型。风险在于,朴素缩小会改变训练动态。一个适合窄模型的 learning rate,可能在更宽的模型上完全失效,因此 cheap search 可能给出误导性答案。
Hydro 通过 parametrization 让这个想法变得可行,具体来说,是对 maximal update parametrization 的系统化适配。它不只是改变 layer width,还会逐层调整 initialization 和 optimizer behavior,让不同宽度模型在训练中保持可比较的 update scale。更工程化地说,Hydro 希望 surrogate 和 target model 对“哪些 hyperparameter configuration 更好”这件事有一致判断。
实现上,Hydro 采用服务化设计。Model Shrinker 用 torch.fx trace PyTorch model,缩放符合条件的 layer,应用 parametrization rules,并在调优任务继续之前做轻量 correctness check。Trial Binder 则通过 grouped hydro.nn module,把许多小 surrogate trial 融合成一个批量执行单元。这很重要,因为单个 surrogate trial 可能太小,无法喂饱一张 A100;fusion 把很多 tiny trial 变成了形状更适合 GPU 的工作负载。
这些组件都重要,但这篇文章想重点看最有 datacenter 味道的部分:Bubble Squeezer。
| 背景组件 | 它给 Bubble Squeezer 提供什么 |
|---|---|
| Model Shrinker | 足够小、可以塞进短暂 bubble 窗口的 surrogate trial |
| Trial Binder | 大小可调的 fused trial bundle,用来适配剩余 memory |
hydro.nn module |
细粒度 pause/resume 的 hook 点 |
集群也是调优系统的一部分
大多数 tuning framework 把集群调度器当作资源售货机。Hydro 则把集群本身纳入优化空间。
Hydro Coordinator 加入了这种集群视角。它最有辨识度的组件是 Bubble Squeezer,目标是长时间运行的 pipeline-parallel 训练任务。Pipeline parallelism 常用于大模型,因为模型会被切成多个 stage,放到多张 GPU 或多个节点上。在常见的 1F1B schedule 中,每个 worker 交替执行 forward 和 backward microbatch,但 schedule 并不是完全致密的。某个 stage 可能完成了一个 microbatch 的 forward pass,然后等待另一个 stage 产生对应的 backward work。这个等待区间就是 pipeline bubble,也就是这里说的流水线空泡。
对大型训练任务来说,bubble 很尴尬。它们很短,反复出现,并且和通信交织在一起。在 bubble 期间,唯一活跃的 kernel 可能只是 NCCL communication,所以即使 GPU 名义上已经分配给训练任务,SM activity 也可能非常低。对普通训练任务来说,这点空间不足以安全运行新任务;但对 Hydro 来说,这是一个入口。
HydroTrial 特别适合放进 bubble 里运行,原因有三点。第一,它们对吞吐波动不敏感:某个 candidate trial 慢一点没关系,只要整个调优任务在前进。第二,它们经过 profiling:Hydro 在把 trial 放到大模型旁边之前,已经知道每个 fused trial 的 memory 和 compute footprint。第三,它们是 elastic 的:fusion count 可以调整,让 trial bundle 适配某个 bubble 剩余的 memory 和 time budget。
Bubble Squeezer 如何挤出空泡
Bubble Squeezer 把 pipeline bubble 变成短暂可用的资源。当一个 pipeline-parallel 大模型训练任务正在运行时,Hydro 会和数据中心调度器协调,获取这些临时机会,并把相应 GPU 标记为只有在 bubble 期间可用。目标很窄也很明确:在不拖慢主训练任务的前提下运行调优工作。
难点不是找到看起来空闲的时间,而是把这段时间变成可用资源,同时不让 colocation 变成 interference。
控制循环有三项职责:
- 发现窗口。 Hydro 修改基于 DeepSpeed 的执行路径,报告 pipeline progress 和 resource consumption。这告诉 Bubble Squeezer 某个 worker 什么时候进入 bubble,以及还有多少 memory 可用。
- 判断窗口是否安全。 Hydro 观察 NCCL kernel 的 CUDA stream 状态,以区分 communication-heavy waiting time 和 compute time。
- 控制访客任务。 Bubble Squeezer 在
hydro.nnmodule 上注册 hook,让 HydroTrial 可以在 forward 和 backward pass 内部细粒度 pause/resume。
第二点尤其关键:直接 colocation 会让两个工作负载盲目竞争,论文报告 direct colocation 会给大模型带来约 12% slowdown。
在 bubble 开始时,Hydro resume 一组 fused surrogate trial;在 bubble 结束时,在大模型重新需要 GPU 前把它们 pause。实现上使用 Linux signal 做 pause/resume 控制,调度决策则由 profiled trial footprint 和当前可用 memory 共同决定。
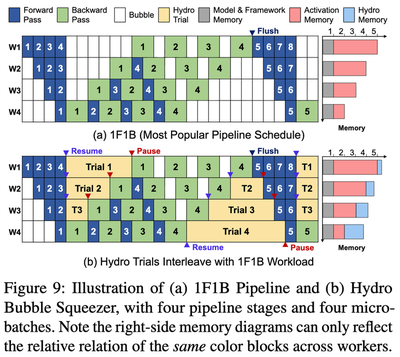
Fusion count 不是固定的。如果某个 pipeline stage 有更多 spare memory,Hydro 可以运行更大的 fused HydroTrial;如果某个 stage 更紧张,就降低 fusion count 或跳过这个 bubble。这正是 Hydro 任务层和集群层两部分之间的小而关键的连接:surrogate scaling 让每个 trial 变小,trial fusion 塑造工作负载,Bubble Squeezer 决定这种工作负载能在某个具体 bubble 里放进去多少。
| Bubble Squeezer 的决策 | 信号或机制 | 为什么重要 |
|---|---|---|
| 什么时候可以运行 HydroTrial? | 来自主训练任务的 pipeline progress report | Bubble 很短而且 stage-local,时机必须跟随 pipeline schedule |
| 应该运行多少 trial work? | Profiled trial footprint 加当前可用 memory | Fusion count 可以按 bubble 增加、降低或跳过 |
| 什么时候必须停? | Fused HydroTrial 中的细粒度 pause/resume hook | 访客任务必须在大模型回到 compute 前让出 GPU |
理想场景是长时间运行的 pipeline-parallel foundation-model 训练任务,它跨多个 stage 和多台服务器。Stage 越多,通常意味着 bubble 越多,也意味着临时执行机会越多。Multi-fidelity tuning 也很适合这种模式,因为许多不 promising 的 trial 可以用 bubble resource 先推进或淘汰,最强的 trial 再获得 exclusive resource。
空泡能换来什么
评估给出了一个很直观的尺度。Hydro 将 ResNet-18 HydroTrial 插入到一个运行在 32 张 A100、4 个 pipeline stage 上的大型 GPT 训练任务中。在原始 GPT training trace 里,bubble 内 SM activity 大约只有 2%。使用 Bubble Squeezer 后,Hydro 把 bubble 期间的 SM utilization 提升到约 50%,同时没有观察到对 GPT 任务的明显 slowdown。
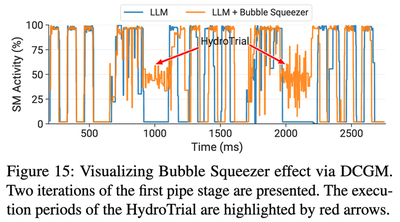
这些调优工作不会像独占 GPU 时那样快,这是预期内的。在实验中,一个 fusion count 为 16 的 HydroTrial 在 bubble 中获得了大约 15% 的 exclusive throughput。但这部分资源基本来自原本闲置的时间片。在一个端到端模拟场景中,当调优任务只有 1 张独占 GPU、而大模型占据大部分集群时,Bubble Squeezer 将 tuning makespan 降低了 2.7x。
Bubble Squeezer 换来了什么。
- Bubble 期间的 SM activity 从约 2% 提升到约 50%。
- Fused HydroTrial 在 bubble 内能达到约 15% 的独占吞吐。
- 它避免了 blind colocation,后者在论文中会给大模型带来约 12% slowdown。
- 在受限的端到端场景中,它把 HPO makespan 降低了 2.7x。
这是 Hydro 最有意思的地方。调度器通常会把已经分配给大训练任务的 GPU 看作不可用。Bubble Squeezer 则往这个 allocation 内部看,找到可重复、边界清晰、低干扰的窗口,让小型、已 profile、可 pause 的工作向前推进。
完整 Hydro 系统仍然很重要:surrogate scaling 让 trial 变便宜,fusion 把 trial 组合成高效 bundle,Bubble Squeezer 再把这些 bundle 放进 pipeline bubble。它们合起来,把 HPO 从 brute-force outer loop 变成了 datacenter-aware service。
当然也有限制。Parametrization 最适合控制 initialization 和 training dynamics 的 hyperparameter,比如 learning rate、batch size、learning-rate scheduler 和 momentum。Dropout、weight decay 这类 regularization 相关选择更难,因为它们更直接依赖模型和数据规模。一些 architecture 也可能需要定制分析。Hydro 并不声称所有 hyperparameter 都可以在所有模型之间转移。
但核心经验是持久的:一旦模型训练进入数据中心规模,超参数搜索就必须同时理解模型、运行时和集群。Hydro 是让这整个 stack 可见的一次尝试。
Paper: Hydro: Surrogate-Based Hyperparameter Tuning Service in Datacenters
Code: S-Lab-System-Group/Hydro