ASTRAEA:GPU 集群里的公平,不只是分到几张卡
 ASTRAEA system design
ASTRAEA system design
公平性听起来很简单,直到一个 GPU 集群真的开始承载各种深度学习任务。
在共享的科研或生产集群里,不同租户提交的任务形态差异很大。有些任务只需要一张 GPU,跑几分钟做调试;有些训练需要很多张 GPU,并且连续运行好几天。只追求利用率的调度器,可能让长任务长期占据集群;过度偏向短任务的调度器,又可能让大型训练一直排队。两类用户都可以很合理地说:这个系统不公平。
ASTRAEA 关注的正是这个问题:多租户 GPU 集群如何在不浪费昂贵加速器的前提下,把公平性真正落到调度决策里?
为什么已有公平性会失效
传统集群调度器经常从“瞬时资源公平”的角度思考问题。比如两个用户共享一个集群,那么在某个时刻,每个人都应该拿到自己的公平份额。对很多大数据任务来说,这个思路很自然,因为任务更容易切分、迁移和重新平衡。
深度学习训练没有这么灵活。训练任务通常需要 gang scheduling:请求的所有 GPU 必须同时分配到位。通信密集型任务对 GPU 拓扑很敏感。抢占也很贵,因为模型状态和优化器状态需要 checkpoint、移动和恢复。如果调度器为了追求公平而频繁重排 GPU,反而可能破坏原本想保护的性能。
另一类方法是 finish-time fairness,也就是判断一个任务是否不晚于它在私有 fair-share cluster 里的完成时间。这个目标有用,但不完整。它强调时间,却容易忽略公平性的空间维度:一个请求更多 GPU 的任务,在单位时间内消耗了更多集群容量。只用完成时间看待 1-GPU 任务和 8-GPU 任务,可能鼓励用户多报资源。
ASTRAEA 的核心想法是直接度量集群真正付出的东西:GPU-time。
长期 GPU-Time 公平性
ASTRAEA 提出了 Long-Term GPU-Time Fairness,简称 LTGF。它不只问“这个租户现在有几张 GPU”,也不只问“这个任务什么时候完成”,而是问:在一段时间内,某个租户或任务实际获得了多少 GPU service,相比它应得的份额是否公平。
这个指标同时捕捉了分配的两个维度:
- 时间维度:任务运行了多久;
- 空间维度:任务运行时占用了多少 GPU。
在租户层面,LTGF 按照预算或 quota 这类权重分配 GPU-time。在任务层面,它在同一个租户内的并发任务之间公平分配 GPU-time。这个两级视角很重要,因为公平集群既要保护组织层面的共享契约,也要照顾每个租户队列里正在等待的具体任务。
这个指标还避免了对剩余时间预测的过度依赖。真实集群里,用户会取消任务,任务会失败,训练吞吐也会随 placement 变化。ASTRAEA 可以根据历史分配记录评估公平性,再用这个信号决定下一步该服务谁。
当调度器用 GPU-time 而不是瞬时 allocation 或完成时间来衡量 service 时,公平性才更容易被推理和修复。
ASTRAEA 如何调度
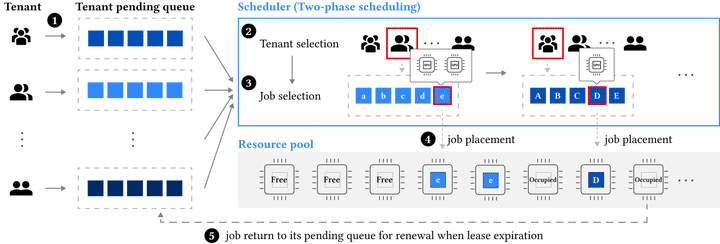
ASTRAEA 使用两阶段调度算法。
第一阶段,它选择 tenant-level fairness index 最低的租户。直白地说,调度器会找到那个相对自己应得份额而言,过去获得 GPU-time 最少的租户。如果这个租户有等待中的任务,并且集群可以放下其中某个任务,ASTRAEA 就会把资源分给它。
第二阶段,ASTRAEA 在该租户内部用 job-level fairness index 选择具体任务。这样即使一个租户整体上被公平对待,它内部的任务队列也不会变得很不公平。任务级策略仍然可以加入实际优先级,但需要受到公平性信号约束。
ASTRAEA 采用 lease-based 调度。它不会在公平性发生变化时立刻抢占,而是给运行中的任务一个租约周期。在租约边界,调度器可以重新安排执行顺序来修复公平性。这是一个务实折中:短租约能更快响应公平性变化,但太短又会增加抢占开销,拉长任务完成时间。ASTRAEA 会为深度学习训练选择一个平衡这些因素的租约长度。
| 调度层次 | 公平性信号 | 调度决策 |
|---|---|---|
| 租户层 | Tenant-level LTGF index | 选择相对自身份额获得 service 最少的租户 |
| 任务层 | Job-level LTGF index | 在该租户内部选择任务,避免队列内部不公平 |
| 租约边界 | 更新后的 allocation history | 在避免频繁抢占的同时修复公平性 |
它带来了什么
ASTRAEA 在真实 GPU 集群 trace 上做了大规模仿真评估,包括 SenseTime 的 Venus trace 和 Microsoft 的 Philly trace。论文报告称,相比已有先进调度器,ASTRAEA 将租户级公平性最多提升 9.42x,将任务级公平性最多提升 10.3x,同时没有牺牲平均任务完成时间。
ASTRAEA 换来了什么。
- 用 long-term GPU-time 衡量公平性,同时覆盖空间和时间。
- 将 tenant-level fairness 最多提升 9.42x。
- 将 job-level fairness 最多提升 10.3x,同时不牺牲平均任务完成时间。
这里重要的经验是:GPU 集群里的公平性不只是政策偏好,它首先是一个测量问题。如果指标忽略 GPU 数量,用户就可能 overclaim;如果指标忽略时间,长任务就可能被饿死;如果指标忽略租户,集群就会违反共享契约;如果指标忽略任务,个体用户仍然会感受到不公平。
ASTRAEA 的贡献,是把深度学习集群中最关键的资源服务单位“长期 GPU-time”变成了可测量、可调度的公平性目标。
Paper: ASTRAEA: A Fair Deep Learning Scheduler for Multi-tenant GPU Clusters
Code: Astraea Artifacts