 System design
System design
Abstract
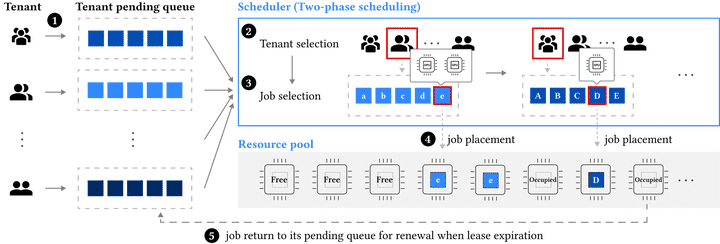
Modern GPU clusters are designed to support distributed Deep Learning jobs from multiple tenants concurrently. Each tenant may have varied and dynamic resource demands. Unfortunately, existing GPU schedulers fail to thoroughly consider the fairness among the tenants and jobs, which can result in unbalanced resource allocation and unfair user experience. In this paper, we present an efficient solution to provide strong fairness while maintaining high scheduling effectiveness in multi-tenant GPU clusters. First, we introduce a novel Long-Term GPU-time Fairness metric, which can comprehensively evaluate the fairness at both the tenant and job levels, based on both the temporal and spatial impacts of resource allocation. Second, we design a new and practical GPU scheduler, ASTRAEA, to enforce the desired fairness among tenants and jobs. Large-scale evaluations show that ASTRAEA can improve tenant fairness by up to 9.42X compared to state-of-the-art schedulers, without sacrificing the average job completion time.
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.