Hydro: Squeezing Hyperparameter Tuning into Pipeline Bubbles
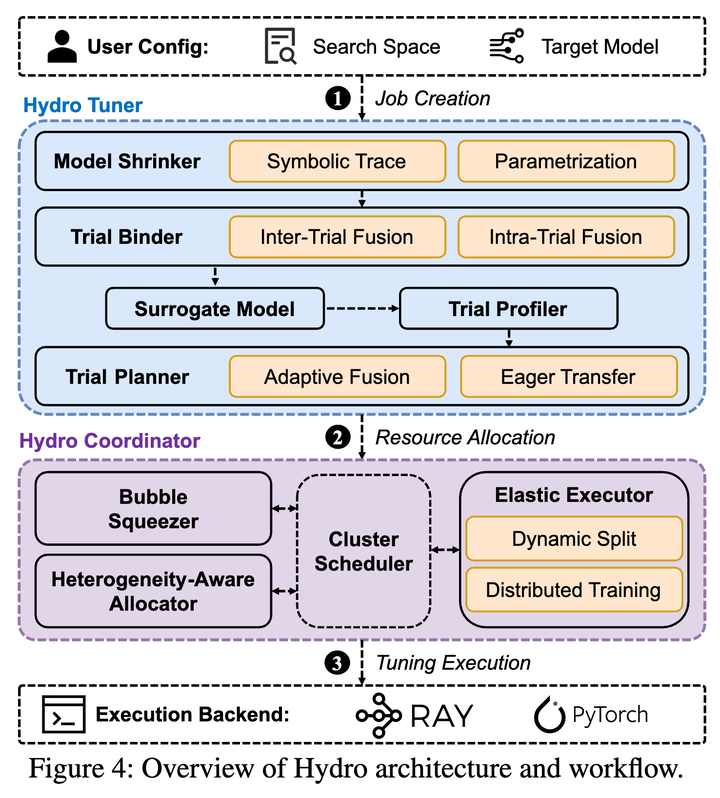 Hydro system design
Hydro system design
Hyperparameter tuning used to feel like a tolerable tax. Train a model many times, sweep a few learning rates and batch sizes, keep the winner. It was expensive, but still part of the normal engineering rhythm.
Then models became large enough that this mental model quietly broke.
If training one model already occupies a large slice of a GPU cluster, a conventional hyperparameter sweep becomes almost absurd: the system asks us to train many near-identical models, most of which exist only to be discarded. Worse, existing tuning frameworks usually see only the resources granted to the tuning job. They do not understand that the cluster around them may contain idle GPU fragments, heterogeneous accelerators, or long-running pipeline-parallel jobs with periodic bubbles.
Hydro started from a simple question: can we make hyperparameter tuning behave less like brute force and more like a systems problem?
Hydro has two sides. At the job level, it makes each trial cheaper by tuning a smaller surrogate model. At the cluster level, it asks a more interesting question: can the datacenter run those cheap trials in GPU time that is currently wasted?
First, Make Trials Small Enough
Hydro’s first move is to avoid tuning the target model directly whenever possible. It shrinks the model, tunes the smaller version, and transfers the discovered hyperparameters back to the original model. The danger is that naive shrinking changes training dynamics. A learning rate that works for a narrow model may fail badly for a wider one, so a cheap search can produce misleading answers.
Hydro makes this idea practical through parametrization, specifically a system adaptation of maximal update parametrization. Instead of only changing layer widths, Hydro adjusts initialization and optimizer behavior layer by layer so that models of different widths preserve comparable update scales during training. In more practical terms, the surrogate and the target model are encouraged to agree on which hyperparameter configurations are good.
The implementation is intentionally service-oriented. Model Shrinker traces the PyTorch model with torch.fx, scales eligible layers, applies the parametrization rules, and runs a lightweight correctness check before the tuning job proceeds. Trial Binder then fuses many small surrogate trials into one batched execution unit through grouped hydro.nn modules. This matters because a single surrogate trial may be too small to keep an A100 busy; fusion turns many tiny trials into a better-shaped GPU workload.
These pieces are important, but in this post I want to focus on the part that feels most datacenter-native: Bubble Squeezer.
| Background component | What it gives Bubble Squeezer | |
|---|---|---|
| Model Shrinker | Surrogate trials small enough to fit into short bubble windows | |
| Trial Binder | Fused trial bundles whose size can be adjusted to match leftover memory | |
hydro.nn modules |
Hook points where Bubble Squeezer can pause and resume execution |
The Cluster Is Part of the Tuning System
Most tuning frameworks treat the cluster scheduler as a resource vending machine. Hydro treats the cluster as part of the optimization surface.
The Hydro Coordinator adds this cluster-level view. Its most distinctive component is Bubble Squeezer, which targets long-running pipeline-parallel training jobs. Pipeline parallelism is common for large models because the model is split into stages placed across multiple GPUs or nodes. In the widely used 1F1B schedule, each worker alternates forward and backward microbatches, but the schedule is not perfectly dense. A stage may finish the forward pass for one microbatch and then wait for another stage to produce the corresponding backward work. That waiting interval is a pipeline bubble.
For the large training job, bubbles are awkward. They are short, appear repeatedly, and are mixed with communication. During a bubble, the only active kernel may be NCCL communication, so SM activity can be extremely low even though the GPU is technically allocated. For a normal training job, this is not enough room to run safely. For Hydro, it is an opening.
HydroTrials are unusually suitable for bubble execution for three reasons. First, they are throughput-tolerant: slowing down one candidate trial is acceptable as long as the tuning job as a whole progresses. Second, they are profiled: Hydro knows the memory and compute footprint of each fused trial before placing it near a large model. Third, they are elastic: the fusion count can be adjusted so that a trial bundle fits the leftover memory and time budget of a bubble.
How Bubble Squeezer Works
Bubble Squeezer turns pipeline bubbles into ephemeral resources. When a pipeline-parallel large-model job is running, Hydro coordinates with the datacenter scheduler to acquire these temporary opportunities and tags the corresponding GPUs as usable only during bubbles. The goal is deliberately narrow: run tuning work without slowing down the primary large-model training job.
The hard part is not finding idle-looking time. The hard part is making that time usable without turning colocation into interference.
The control loop has three responsibilities:
- Detect the opening. Hydro modifies the DeepSpeed-based execution path to report pipeline progress and resource consumption. This tells Bubble Squeezer when a worker is entering a bubble and how much memory is still available.
- Check that the opening is safe. Hydro watches CUDA stream status for NCCL kernels so it can distinguish communication-heavy waiting time from compute time.
- Control the guest work. Bubble Squeezer registers hooks on
hydro.nnmodules so a HydroTrial can pause and resume at fine granularity, including inside forward and backward passes.
That second responsibility is crucial: direct colocation would let two workloads compete blindly, and the paper reports about 12% slowdown to the large model under direct colocation.
At the start of a bubble, Hydro resumes a set of fused surrogate trials. At the end of the bubble, it pauses them again before the large model needs the GPU. The implementation uses Linux signals for pause and resume control, while the scheduling decision is guided by the profiled trial footprint and the currently available memory.
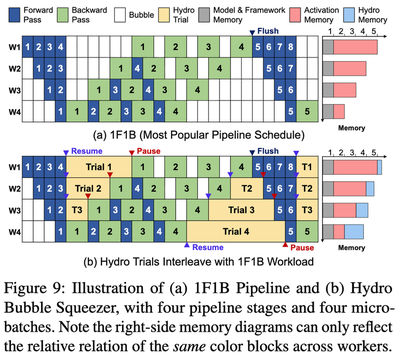
The fusion count is not fixed. If a pipeline stage has more spare memory, Hydro can run a larger fused HydroTrial. If the stage is tighter, Hydro can reduce the fusion count or skip that bubble. This is the small but important connection between the job-level and cluster-level parts of Hydro: surrogate scaling makes each trial small, trial fusion shapes the work, and Bubble Squeezer chooses how much of that shaped work can fit into a specific bubble.
| Bubble Squeezer decision | Signal or mechanism | Why it matters |
|---|---|---|
| When can a HydroTrial run? | Pipeline progress reports from the large-model job | Bubbles are short and stage-local, so timing must follow the pipeline schedule |
| How much work should run? | Profiled trial footprint plus available memory | The fusion count can be increased, reduced, or skipped per bubble |
| When should work stop? | Fine-grained pause/resume hooks in fused HydroTrials | Guest work must yield before the large model returns to compute |
The ideal case is a long-running pipeline-parallel foundation-model job with multiple stages across multiple servers. More stages usually mean more bubbles and more ephemeral execution slots. Multi-fidelity tuning also fits especially well, because many unpromising trials can be advanced or eliminated using bubble resources while the strongest trials later receive exclusive resources.
What the Bubbles Buy
The evaluation gives a useful sense of scale. Hydro interleaves ResNet-18 HydroTrials with a large GPT training job running on 32 A100 GPUs across 4 pipeline stages. In the original GPT training trace, SM activity inside bubbles is about 2%. With Bubble Squeezer, Hydro raises that bubble-period SM utilization to about 50% without evident slowdown to the GPT job.
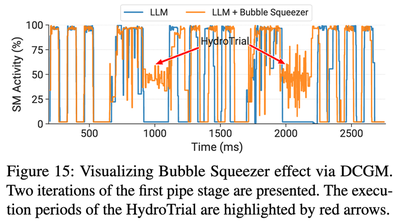
The tuning work does not run as fast as it would on an exclusive GPU, and that is expected. In the experiment, a HydroTrial with fusion count 16 obtains about 15% of its exclusive throughput while living inside bubbles. But the resource is effectively reclaimed from otherwise idle intervals. In a simulated end-to-end setting where the tuning job has only 1 exclusive GPU because the large model occupies most of the cluster, Bubble Squeezer reduces tuning makespan by 2.7x.
What Bubble Squeezer buys.
- It raises bubble-period SM activity from about 2% to about 50%.
- It lets a fused HydroTrial make progress at about 15% of exclusive throughput inside bubbles.
- It avoids the blind-colocation failure mode, where the paper reports about 12% slowdown to the large model.
- It reduces HPO makespan by 2.7x in the constrained end-to-end setting.
This is the part of Hydro I find most interesting. A scheduler usually sees a GPU assigned to a large training job as unavailable. Bubble Squeezer looks inside that allocation and finds repeatable, bounded, low-interference windows where small, profiled, pauseable work can make progress.
The broader Hydro system still matters: surrogate scaling makes trials cheap, fusion shapes them into efficient bundles, and Bubble Squeezer places those bundles into pipeline bubbles. Together, these pieces turn HPO from a brute-force outer loop into a datacenter-aware service.
There are limits. Parametrization is most effective for hyperparameters that control initialization and training dynamics, such as learning rate, batch size, schedulers, and momentum. Regularization-related choices like dropout and weight decay are harder because they depend more directly on model and data scale. Some architectures may also require tailored analysis. Hydro does not claim that every hyperparameter can be transferred for every model.
But the central lesson is durable: once model training becomes datacenter-scale, hyperparameter search must understand the model, the runtime, and the cluster. Hydro is one attempt to make that full stack visible.
Paper: Hydro: Surrogate-Based Hyperparameter Tuning Service in Datacenters
Code: S-Lab-System-Group/Hydro
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.