ASTRAEA: Fairness Is More Than Counting GPUs
 ASTRAEA system design
ASTRAEA system design
Fairness sounds simple until a GPU cluster starts running real deep learning workloads.
In a shared research or production cluster, different tenants submit jobs with very different shapes. Some jobs need one GPU for a quick debugging run. Others need many GPUs and run for days. A scheduler that only optimizes utilization may let long jobs dominate the cluster. A scheduler that aggressively favors short jobs may make large training jobs wait forever. Both users can reasonably say the system is unfair.
ASTRAEA was built around this problem: how should a multi-tenant GPU cluster enforce fairness without wasting expensive accelerators?
Why Existing Fairness Breaks
Traditional cluster schedulers often think in terms of instantaneous resource fairness. If two users share a cluster, each should receive a fair share of resources at the current moment. This works well for many big-data workloads, where tasks are easier to split, migrate, and rebalance.
Deep learning training is less flexible. Jobs usually require gang scheduling: all requested GPUs must be allocated together. Communication-heavy jobs are sensitive to GPU topology. Preemption is also costly because model state must be checkpointed, moved, and restored. If a scheduler tries to enforce fairness by frequently reshuffling GPUs, it can destroy the performance it was meant to protect.
Another approach is finish-time fairness, where the scheduler asks whether a job would finish no later than it would in a private fair-share cluster. That is useful, but incomplete. It focuses on time and can miss the spatial side of fairness: a job that asks for more GPUs consumes more cluster capacity per unit time. Treating a 1-GPU job and an 8-GPU job only through finish time can create incentives to overclaim resources.
ASTRAEA’s core idea is to measure what the cluster is actually spending: GPU-time.
Long-Term GPU-Time Fairness
ASTRAEA introduces Long-Term GPU-Time Fairness, or LTGF. Instead of asking only “how many GPUs does a tenant have right now?” or “when will this job finish?”, LTGF asks how much GPU service a tenant or job has received over a period of time compared with how much it deserves.
This captures both dimensions of allocation:
- temporal impact: how long the job runs;
- spatial impact: how many GPUs it occupies while running.
At the tenant level, LTGF distributes GPU-time according to tenant weights, such as budget or quota. At the job level, it distributes GPU-time fairly among concurrent jobs inside a tenant. This two-level view is important because a fair cluster should protect both the organization sharing contract and the individual jobs waiting inside each tenant’s queue.
The metric also avoids relying on fragile remaining-time prediction. In real clusters, users cancel jobs, jobs fail, and training throughput changes with placement. ASTRAEA can evaluate fairness from past allocation history, then use that signal to decide who should receive service next.
Fairness becomes easier to reason about once the scheduler measures service in GPU-time instead of only instantaneous allocation or completion time.
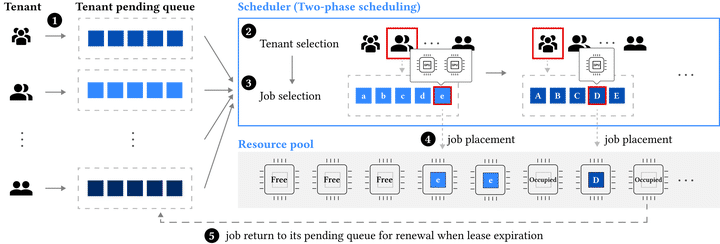
How ASTRAEA Schedules
ASTRAEA uses a two-phase scheduling algorithm.
First, it selects the tenant with the lowest tenant-level fairness index. In plain language: the scheduler finds the tenant that has received the least GPU-time relative to what it should have received. If that tenant has pending jobs and the cluster can place one of them, ASTRAEA grants resources to it.
Second, ASTRAEA selects a job within that tenant using the job-level fairness index. This keeps one tenant’s internal queue from becoming unfair even when the tenant as a whole is being treated fairly. Job-level policies can still incorporate practical priorities, but they are constrained by the fairness signal.
The scheduler is lease-based. Instead of preempting whenever fairness changes, ASTRAEA gives a running job a lease term. At lease boundaries, the scheduler can rearrange execution order to repair fairness. This is a practical compromise: short leases improve fairness response, but too-short leases increase preemption overhead and hurt job completion time. ASTRAEA chooses a lease length that balances those forces for deep learning training.
| Scheduling layer | Fairness signal | Scheduling decision |
|---|---|---|
| Tenant level | Tenant-level LTGF index | Pick the tenant that has received the least service relative to its share |
| Job level | Job-level LTGF index | Pick a job inside that tenant without making the tenant’s queue unfair |
| Lease boundary | Updated allocation history | Repair fairness while avoiding constant preemption |
What It Buys
ASTRAEA was evaluated with large-scale simulations on real GPU cluster traces, including SenseTime’s Venus trace and Microsoft’s Philly trace. The paper reports that ASTRAEA improves tenant-level fairness by up to 9.42x and job-level fairness by up to 10.3x compared with state-of-the-art schedulers, without sacrificing average job completion time.
What ASTRAEA buys.
- It measures fairness in long-term GPU-time, combining space and time.
- It improves tenant-level fairness by up to 9.42x.
- It improves job-level fairness by up to 10.3x without sacrificing average job completion time.
The important lesson is that fairness in GPU clusters is not just a policy preference. It is a measurement problem. If the metric ignores GPU count, users can overclaim. If it ignores time, long-running jobs can be starved. If it ignores tenants, the cluster violates sharing agreements. If it ignores jobs, individual users still experience unfairness.
ASTRAEA’s contribution is to make fairness measurable in the unit that matters most for deep learning clusters: long-term GPU-time.
Paper: ASTRAEA: A Fair Deep Learning Scheduler for Multi-tenant GPU Clusters
Code: Astraea Artifacts
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.